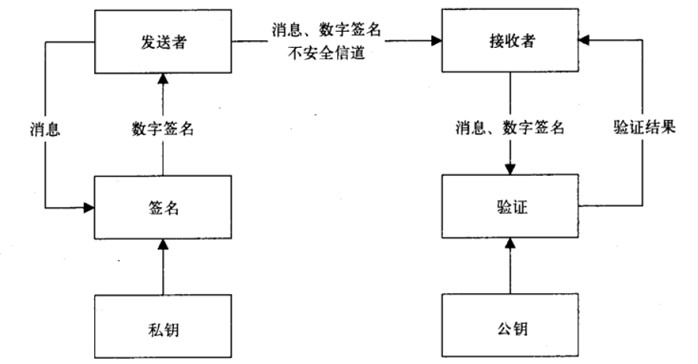
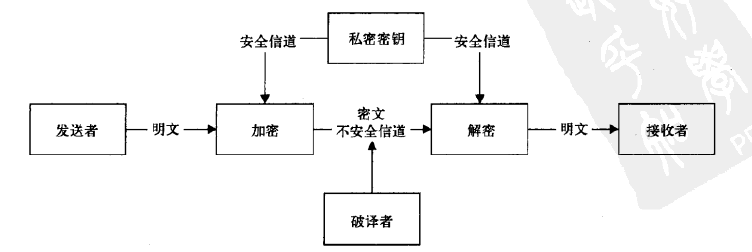
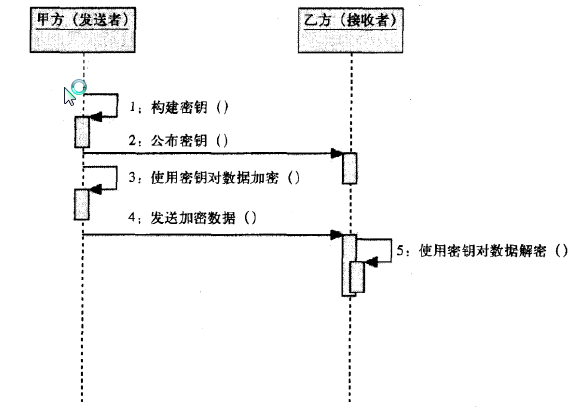
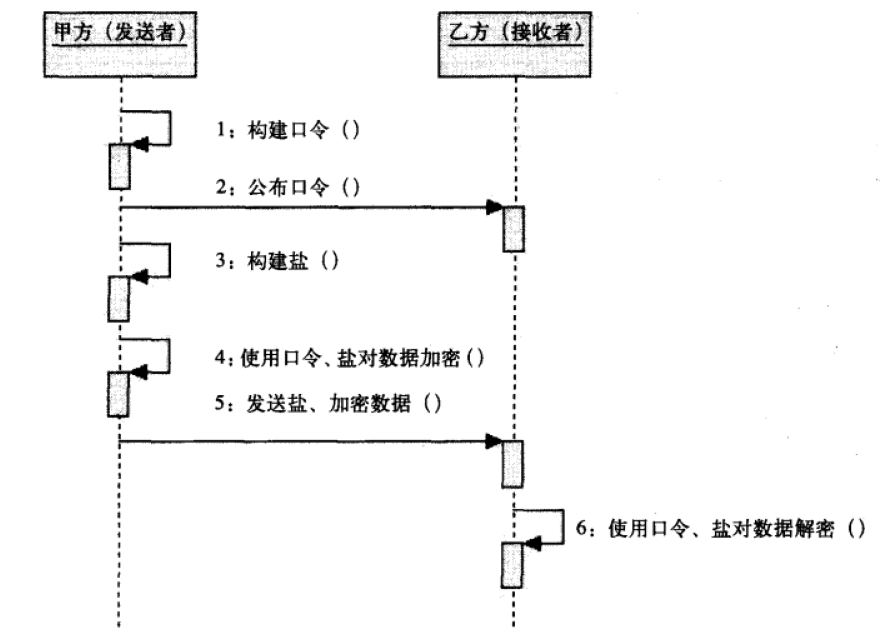
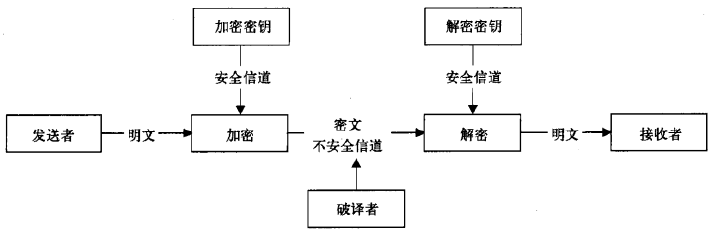
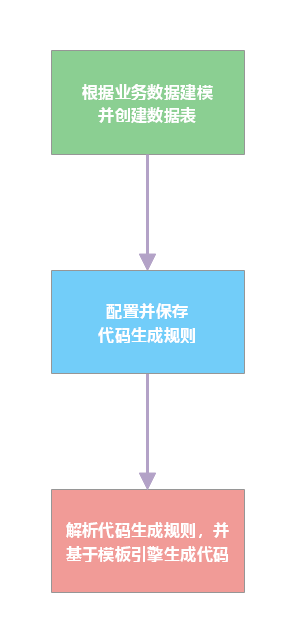
建立数据模型就是提取业务实体的数据特征,抽象为数据表,建立表间关系。制作 ER 图的过程就是数据建模。市面上常见的低代码平台均提供了丰富的控件,可以拖拽完成数据模型搭建。此外,数据模型搭建与表单展示合二为一,每完成一个数据表的创建,就自动生成了该表的增删改查功能及相关页面,进而隐藏了数据库设计、前端开发这些专业技术。其实,这也就是我们常说的表单引擎。
大部分的低代码平台都采用了非常经典的 RBAC(Role-Based Access Control )模型管理用户权限,简单来说就是将拥有相同权限的用户添加为相同角色,通过为角色分配权限,实现了“用户——角色——权限”的授权模式。由于企业是一个组织,一般都会有部门的概念,所以也可以将部门添加到某个角色,实现“用户——部门——角色——权限”的授权模式。
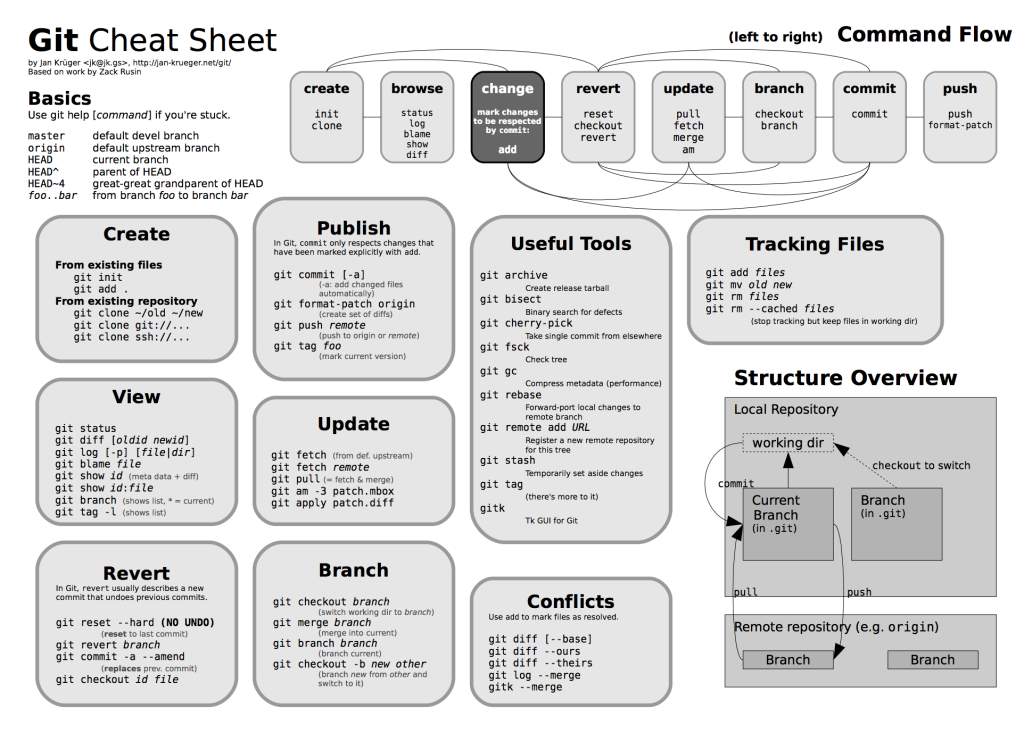
[alias] a = add amend = commit --amend c = commit ca = commit --amend ci = commit -a co = checkout d = diff dc = diff --changed ds = diff --staged f = fetch loll = log --graph --decorate --pretty=oneline --abbrev-commit m = merge one = log --pretty=oneline outstanding = rebase -i @{u} s = status unpushed = log @{u} wc = whatchanged wip = rebase -i @{u} zap = fetch -p
To https://github.com/yourusername/repo.git ! [rejected] mybranch -> mybranch (non-fast-forward) error: failed to push some refs to 'https://github.com/tanay1337/webmaker.org.git' hint: Updates were rejected because the tip of your current branch is behind hint: its remote counterpart. Integrate the remote changes (e.g. hint: 'git pull ...') before pushing again. hint: See the 'Note about fast-forwards' in 'git push --help' for details.
(my-branch)$ git status ## On branch my-branch ## Your branch is ahead of 'origin/my-branch' by 2 commits. ## (use "git push" to publish your local commits) #
## On branch develop ## Your branch is up-to-date with 'origin/develop'. ## Changes to be committed: ## (use "git reset HEAD <file>..." to unstage) # ## modified: file1.txt
然后, 正常提交。
Note: Spike solutions are made to analyze or solve the problem. These solutions are used for estimation and discarded once everyone gets clear visualization of the problem. ~ Wikipedia.
我把几个提交(commit)提交到了同一个分支,而这些提交应该分布在不同的分支里
假设你有一个master分支, 执行git log, 你看到你做过两次提交:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
(master)$ git log
commit e3851e817c451cc36f2e6f3049db528415e3c114 Author: Alex Lee <alexlee@example.com> Date: Tue Jul 22 15:39:27 2014 -0400
Bug #21 - Added CSRF protection
commit 5ea51731d150f7ddc4a365437931cd8be3bf3131 Author: Alex Lee <alexlee@example.com> Date: Tue Jul 22 15:39:12 2014 -0400
Bug #14 - Fixed spacing on title
commit a13b85e984171c6e2a1729bb061994525f626d14 Author: Aki Rose <akirose@example.com> Date: Tue Jul 21 01:12:48 2014 -0400
First commit
让我们用提交 hash(commit hash)标记 bug (e3851e8 for #21, 5ea5173 for #14).
首先, 我们把master分支重置到正确的提交(a13b85e):
1 2
(master)$ git reset --hard a13b85e HEAD is now at a13b85e
现在, 我们对 bug #21 创建一个新的分支:
1 2
(master)$ git checkout -b 21 (21)$
接着, 我们用 cherry-pick 把对 bug #21 的提交放入当前分支。 这意味着我们将应用(apply)这个提交(commit),仅仅这一个提交(commit),直接在 HEAD 上面。
(master)$ git checkout -b my-branch-help Switched to a new branch 'my-branch-help' (my-branch-help)$ git reset --hard 4e3cd85 HEAD is now at 4e3cd85 foo.txt added (my-branch-help)$ ls README.md foo.txt
pick a9c8a1d Some refactoring pick 01b2fd8 New awesome feature pick b729ad5 fixup pick e3851e8 another fix
## Rebase 8074d12..b729ad5 onto 8074d12 # ## Commands: ## p, pick = use commit ## r, reword = use commit, but edit the commit message ## e, edit = use commit, but stopfor amending ## s, squash = use commit, but meld into previous commit ## f, fixup = like "squash", but discard this commit's log message ## x, exec = run command (the rest of the line) using shell # ## These lines can be re-ordered; they are executed from top to bottom. # ## If you remove a line here THAT COMMIT WILL BE LOST. # ## However, if you remove everything, the rebase will be aborted. # ## Note that empty commits are commented out
pick a9c8a1d Some refactoring pick 01b2fd8 New awesome feature s b729ad5 fixup s e3851e8 another fix
你可以在接下来弹出的文本提示框里重命名提交(commit)。
1 2 3 4 5 6 7 8 9 10 11
Newer, awesomer features
## Please enter the commit message for your changes. Lines starting ## with '#' will be ignored, andanempty message aborts the commit. ## rebase in progress; onto 8074d12 ## You are currently editing a commit while rebasing branch 'master'on'8074d12'. # ## Changes tobe committed: # modified: README.md #
如果成功了, 你应该看到类似下面的内容:
1
(master)$ Successfully rebased and updated refs/heads/master.
这意味着你 rebase 的分支和当前分支在同一个提交(commit)上, 或者 领先(ahead) 当前分支。 你可以尝试:
检查确保主(master)分支没有问题
rebase HEAD\~2 或者更早
有冲突的情况
如果你不能成功的完成 rebase, 你可能必须要解决冲突。
首先执行 git status 找出哪些文件有冲突:
1 2 3 4 5 6 7
(my-branch)$ git status On branch my-branch Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
在这个例子里面, README.md 有冲突。 打开这个文件找到类似下面的内容:
1 2 3 4 5
<<<<<<< HEAD some code ========= some code >>>>>>> new-commit
这就是 git reflog 的目的, reflog 记录对分支顶端(the tip of a branch)的任何改变, 即使那个顶端没有被任何分支或标签引用。基本上, 每次 HEAD 的改变, 一条新的记录就会增加到reflog。遗憾的是,这只对本地分支起作用,且它只跟踪动作 (例如,不会跟踪一个没有被记录的文件的任何改变)。
1 2 3 4
(master)$ git reflog 0a2e358 HEAD@{0}: reset: moving to HEAD\~2 0254ea7 HEAD@{1}: checkout: moving from 2.2 to master c10f740 HEAD@{2}: checkout: moving from master to 2.2